Blog
Back To Nextfli
November 30th, 2021 (permalink)
Recently I've been visiting my various projects; there's a new version of my virtual modular synthesizer (not that anyone cares, apparently); I merged a bunch of things to SoLoud but it's not ready for a new stable release yet, and then I started looking at where I was with Spectrum Next stuff, and picked up Nextfli.
Nextfli started as a more or less generic Autodesk FLIC player (fli/flc), but I kept hitting some issues with it, and eventually figured I'd need to control the encoder in order to debug it.
And while at it, let's extend the format so it's more target device friendly. Okay, let's just toss the FLI format itself and make a new delta-frame 8bit paletted animation format. But FLI comes first.
So I wrote a new FLC encoder, and added new blocks to it that are easier to parse and compress better. This is relateively easy to do, as the FLI format is really line based, while I could just take the whole frame as one linear data block, so my RLE runs can be longer. I also added some "LZ" schemes which easily beat the FLI schemes if you have something that moves, which is rather often the case.
The FLI formats were also designed for single-buffered output, while I have a double buffered one. That lets me read anywhere from the previous frame.
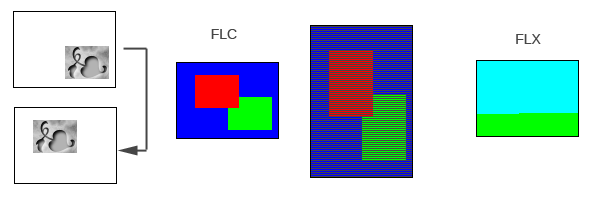
Let's look at a very simple example that gives unfair advantage to the new blocks. We have two frames where a block moves from one place to another. For FLC, parts of the image are unchanged (blue), parts can be filled with a single color (green), and parts need to be stored as is in the FLC file (red). To make things worse, things are stored scanline by scanline, so there's a repeating pattern of skip-fill-skip-skip-fill-skip-skip.
In comparison, the LZ blocks can just say "let's copy all of this from previous frame" twice (cyan and green). Performance wise it doesn't matter if we're filling, skipping or copying, since in double buffered environment the "skip" becomes "copy from previous frame".
In the end the "classic" FLI blocks exist in my encoder primarily for comparison, but my encoder can output both FLC files as well as the more specnext-specific FLX files.
Everything is hardcoded for the spectrum's 9 bit color space and 256x192 pixel resolution, although those limitations could be easily relaxed.
One fun fact about the FLI format: the FLI "8 bit delta" frames are documented as having one byte of "how many lines to skip" encoded in every line, but that byte doesn't actually go there. And talking fun facts, the "16 bit delta" has a specific encoding for "update only the last pixel of scanline". I didn't bother outputting any of that encoding. How often does that happen anyway? If the format had some kind of "scroll sideways" opcode that might make sense, but as it is... I have no idea what they were thinking.
I still need to rewrite the actual player on the next, of course, but the encoder side is starting to look pretty solid now.
Tobii Eye Tracker 5
November 4th, 2021 (permalink)
I've been interested in various technologies that extend the computing / gaming experience. I bought the leap motion controller when it was new. I had some game ideas for it, but never really ended up using it for anything.
In the same vein, I bought the Tobii eye tracker. Best case it would be a sort of limited VR without a headset, at worst it might be useful for something.
While waiting for the package to arrive I figured I'd look at the SDK, and found out that there's basically three options: unity, unreal, or some kind of legal process. You can get a "try but don't actually use" license SDK for free, though. So I didn't look deeper into it.
Technically the tobii is a well built metal bar that is magnetically connected to a little tray you tape to the bottom of your monitor. It plugs into USB, which apparently isn't even USB3. Once connected, windows installed drivers as well as the "tobii experience" control panel which is used for calibrating as well as setting up system options. No cd:s, no usb sticks, no manual downloads needed.
It's also a windows hello camera (i.e, login via face recognition), but win10 needed a reboot to recognize it as such.
Whole installation experience was really easy. When things are up and running you get to a demo thingy where you realize that the system has more latency than you'd expect (..which is kinda understandable seeing that your eyes are tiny bit faster than the computer can render..), and accuracy depends on how far you're sitting. Calibration wants you to sit a bit closer than I'm comfortable.
On operating system side, it hooks into the alt-tab application change thing, where you can pick the app you want to change to by looking at it. Very neat. Too bad I don't alt-tab all that much. You can also enable mouse cursor warping to where you're looking, which I didn't find too useful, but I can see how getting used to that may be very frustrating when you have to use a system that doesn't have that again. There's also a "dim the screen when you're not looking" security option, which can be really useful in some environments.
I installed a bunch of games to try things out, and here's some quick notes.
Shadow of tomb raider gives you a "enlarged screen" where staring at sides of the screen tilts the camera a bit.
This is a very subtle effect, especially if you're playing with a mouse, as you're probably used to moving the camera where you're looking anyway. Might make more sense if you played with a gamepad.
Talos principle lets you adjust the amount and speed of the "enlarged screen" effect, and it's much more usable there. I did not play for an extended time, though, so it might get annoying. Talos also hides UI when you're not looking, which is neat.
qube2: enlarged screen is subtle, again. Additionally you can aim with your gaze which is fun, but started straining my eyes after a while. Seeing on the screen where you're looking is also fun with subtitles, kinda like those karaoke "ball bouncing on text" thingies.
Project cars 2: could not get working. There's a FAQ on the site for a commandline option, but that did nothing. Might be related to the fact that I also have a VR headset, so the config may conflict (you need to run the game in VR mode for the eye tracking support)
Distance: Could not get working. Nothing in menus. Nothing on steam forums. No FAQ. And given the game name, googling for help is pointless.
Assassins creed: origins. "Enlarged screen" is subtle again. Aiming with the bow snaps to where you were looking, which is neat. The game also lists other features like if you stare at NPCs they get suspicious.
Overload: secondary weapons (missiles) launch in the direction you're looking.
F1 2020: can track both eyes and head tilt, and adjust these a bit. Since this is a game I play with a gamepad instead of "mouse aiming", the eye/head tilt tracking made a lot more sense and makes a difference.
So from a quick try, my conclusions:
Does it work? Yes.
Is it well used in games? No.
Is it worth the price tag? Depends.
Would I recommend it? Probably not.
There's some use cases like being a streamer and showing your viewers where your eyes point at which sounds really useful. Or if you are a pro-level competing MOBA player, it can be used to analyze your play with heat maps and such. Similarly it could be used for UI testing. But for a joe random gamer, it doesn't, in my opinion, add a lot of value. I have a feeling it could, though!
I started pondering what I was missing, and realized that what I really want is head tracking, not just eye tracking. The tobii hardware should easily deal with that, the games are just not using it.
Pondering further, I started thinking how I could make a "ghetto" demo of head tracking by taping a piece of paper on my head and doing some primitive image recognition stuff with a webcam. The math to turn your monitor into a "window" doesn't feel all that complicated. Maybe I'll try to find time to whip something together.
But yeah, the tobii should make that trivial.
Musing On 8 Bit Audio Compression
August 1st, 2021 (permalink)
While doing some video compression on the ZX Spectrum Next, I found it ironic that raw 8 bit audio (even at a low sample rate) ended up taking as much space as the accompanied video, so I started pondering on what to do about it.
Looking at the schemes that exist, there's no really good clear option. On Amiga, samples could be delta encoded and then RLE compressed. Since my target is a 8 bit micro and I'm also doing video decoding, I really don't have the processing power to do generic decompression. And the compression ratios, even with delta encoding, aren't too hot.
Schemes like ADPCM target 16 bit audio, but we can look at what they're based on. A couple simple DPCM (without A) schemes come to mind: for each input, compare it with the previous output and try to modify the value to be as close to the input as possible, and send it out. Repeat.
Two 4-bit schemes come to mind: first would be to use a 16 value table of values to add; these could either be evenly spaced (0, 17, 34, 51, 68, 85, 102, 119, 137, 154, 171, 188, 205, 222, 239), or not - it would take some experimentation to find what kinds of values work well.
The second scheme would use 1 bit to say whether a bit should be set or cleared, and 3 to say which bit (as 222=8). The obvious negative side of this scheme is that half of the potential opcodes are NOPs, so the first scheme probably transfers more data.
Both of the 4 bit schemes yield lossy 1:2 compression with (relatively) low processing power. Whether the results are better or worse than simply halving the sample rate requires testing.
To make things worse for these schemes, they need to sound better than a simpler alternative: we could just interpolate every second sample. Or interpolate even more of the samples for higher "compression".
Another, completely different scheme would be to generate 256 grains out of the source data and just store the grains plus indexes to the grains. This scheme has rather high compression potential, but I don't know if it will work at all. In addition to the higher compression potential, being byte based it should be even faster to decompress than the 4-bit schemes.
To find the grains to store, I thought of the following scheme:
Each potential grain exists as a point in N dimensional space; N being the number of samples in the grain. Find the dimension with the highest difference between smallest and largest value, and split the space in two along that axis. Repeat splitting subspaces until the desired number of subspaces - 256 - is generated.
Once this is done, we average the samples in each subspace. This, unfortunately, tends towards 0.5 when the number of samples and/or dimensions is high. One solution is to just pick a random grain from the subspace, or to normalize the averaged values to get back to near the original dynamic range.
One potential addition which may or may not help is to rotate the samples in the grain so that the smallest (or biggest) value comes first.
Whether this scheme works at all remains to be seen. It makes sense, logically, but in practice it may blow up the audio so badly that it's unusable. One fun fact for this scheme is that there's no real reason why it wouldn't work for stereo samples too.
The compression ratio depends on the grain size (gs):
output = gs * 256 + input / gs
So for 64k samples and 4 sample grains, the compression ratio is 26%. Going up to 16 sample grains, the compression goes to 13%. For 1 megabyte of samples and 16 sample grains, 7%. Going the other way, for 8k samples and 2 sample grains, the compression ratio is 56%.
The likelihood that single set of 256 grains would sound good over 1 megabyte of samples is quite low, though, so it might make sense to split input sample into smaller chunks and compress them separately. On the other hand, switching from one set of grains to another may cause an audible difference, so this may not be a great idea. I guess one could switch grains gradually over time, but that gets rather complicated.
For granular synthesis to sound nice we'd need to overlap the grains with an envelope, but this would take way too much processing power. We're talking 8 bits, after all.
Finally - how to know which scheme is the best? I could calculate absolute difference with the source data, but with audio you never know if that matters. You can literally inverse the whole source and it will sound exactly the same. Or you can shift by a single sample, for instance. Or one could generate waterfall FFT images and compare those - that would at least show if signals are lost or gained.. but I suppose I should just play it by ear.
I'm pretty sure all of the results will be horrible.
Sassy Audio Spreadsheet
May 31st, 2021 (permalink)
Sooo.. after the previous blog post I kept thinking about that virtual modular thingy, and even played around with a graph editor for a bit.
Then I recalled an idea I had a long time ago: the audio generation of modular synths kind of remind me of spreadsheets. You have cells with values or formulas, and refer to other cells.
After a bit of tinkering..
I don't really know if the project is really going to go anywhere, but I put it on itch.io for the heck of it, maybe a lot of people want to buy it. Who knows? (It hasn't, so far)
After getting the first versions off the ground a friend and much more of a music person than me, Antti Tiihonen made a few test spreadsheets that really opened my eyes to what it can do.
Once the 1.0 beta was built I made a video which attracted some attention, with mentions in music industry sites all over the place. The mentions were generally positive, and reactions were mostly humorous. You can check the trailer out here:
Like I realized some time ago, a lot of synth stuff is actually pretty simple, and it's more about user interfaces. I'm not sure if spreadsheet is the worst possible user interface when it comes to synthesizers, but that's what the MIDI integration is for - you can very easily connect your spreadsheet creation to physical encoders and pots of your MIDI gear.
I'm currently slowly working on beta 1.8 - hopefully with ASIO support - but the 1.7 beta that's available to download off itch.io (widget above) is already pretty powerful, with tons of additions after the 1.0 beta.
Some internals that may be of interest;
Ocornut's IMGUI library (relatively) recently added grid support which is the basis of the editor. Each of the grid cells contains a formula, basically what you might find on a single line of a programming language. This can get pretty complicated.
The formula is parsed into a string of tokens, so we get things like "2", "+", "3". At this point simple constant folding is performed, by trying to evaluate each operation or function; if all components are constant, we can do the calculation here and replace the formula (or part of the formula) with a constant value.
The constant folding is very limited, meaning that if you have, say, 2x3, a smart constant folder could say that's 6*x, but since we're not reordering (or even building a tree), we can't. It's not perfect, but it's something.
Next, the tokens are re-arranged to reverse polish notation, so "2", "+", "3" turns into "2", "3", "+"; in this form the tokens can already be executed via a simple algorithm: if token is a constant, push it to stack. Otherwise, pop the number of arguments, perform calculation and push the result. There's further small rules for parentheses and functions, but that's the gist of it.
This works, but isn't exactly fast. Enter JIT compiling - using a library called xbyak. Xbyak generates x64 opcodes and handles things like memory protection changes, but you still need to know x64 assembly and calling conventions and stuff.
Using xbyak the opcode array turns into a single huge x64 function with zero loops, but a lot of function calls. Some things I wrote out, so if you add two variables together, it will not produce a function call, but a call to low pass filtering definitely does. Just leaving out the need to loop through all of the spreadsheet cells sped things up a lot.
Compared to running the opcodes directly, the stack uses the actual machine stack instead of a virtual one, and after tinkering with it for a while I realized that I should just keep the top of the stack in a register, which means that if you're only calling single parameter functions, I don't need to push or pop the stack at all.
After the initial interest for Sassy started to wane, I also started to feel a bit tired on working on it, and thus the release rate has dropped. I hope I'll get the 1.8 beta out this summer, but I'm not holding my breath.
In other news, here's a z80 assembly tutorial where I write a complete game for the zx spectrum from scratch in 100% z80 assembler, along with a rather thorough look at the AY sound chip.
Synthalizer thoughts
February 14th, 2021 (permalink)
When the Atanua (logic sim) project was nearing its end I added some audio capabilities to it, but that didn't really work out due to Atanua's low simulation clock of 1kHz. Later on I started thinking about audio generation again, pondering if a spreadsheet would be a nice approach. Again, Atanua's node graph made more sense, as with a spreadsheet you can't really see the connections between things.
What I was reinventing was basically euro rack style modular synthesis in software. This is definitely not a new idea, there are free and commercial implementations out there. But for some reason I felt like I still wanted to write my own.
Today, instead of trying to massage Atanua's editor into something I could use, I'd use Ocornut's Dear Imgui and some implementation of node editor on top of it. There are several, I just linked thedmd's one, as that looks promising.
To be usable, the synth should be able to output at least 44k samples per second, so let's say it should be at least 50 times faster than Atanua was. Primary reason for Atanua's slowness is that its logic was actually pretty heavy; instead of simply saying a signal is low or high, Atanua also did stuff like not connected wires, error propagation, weak signals, etc. Each block had to have logic that dealt with various states, so even if you had a simple "and" operation, you had to deal with all of that.
I don't see any reason why the synth would have to deal with anything that complex. Let's think of a simple attenuator block (i.e, volume control);
.-----.
|c |
| | |
|i + o|
| | |
| |
'-----'
There's two inputs: input signal and control voltage, and one output. The control voltage is also biased based on the user input slider, so that might be considered a third input, but in practice it would be member of the node itself. The code might look something like:
void attenuate(float control, float input, float &output)
{
output = input * (control + mBias);
}
That's pretty lightweight compared to what Atanua had to do. Of course, to call that function there needs to be a pile of code that goes through all the nodes, deals with what output goes to what input, and there needs to be some logic stating what the signals should be if some inputs are not connected; i.e, if the attenuator doesn't get a control voltage, the "bias" will be the only thing that affects the result, so the control would default to zero. That could be dealt by having an implicit "zero" wire that's connected to everything if there's no wire, so no additional logic is needed.
This by itself might be fast enough, but what could be done to go faster? The first idea is to pass buffers along instead of single samples. Unfortunately that would mess up feedback effects, which would be a bummer. I'm pretty sure we could get away with passing a small number of samples though, which would allow the use of SSE instructions...
One option would be to let the modules specify the granularity of samples they accept, and make the framework add buffers in the inputs as needed. All of the modules add some latency to the system, some more than others, so that wouldn't be a total nightmare. Maybe.
Another thing I thought of when pondering how to make Atanua run faster would be to turn the graph into code. There's a few options that I can find. One would be to write the modules in Lua and use Luajit, which would already run on various platforms, but would make things like handling 4 samples at a time via SSE a bit difficult. I'm sure there are other scripting languages with jit out there, but I haven't studied them too deeply.
Second option would be to roll my own language, which is kind of tempting, but when we get to even slightly more complicated routines that would be needed, like noise (aka pseudorandom number generator), the required language features would get quickly out of hand. (And don't get me started on fft..)
At least the language would require the ability to call pre-existing c routines. Also, if I wanted anyone else to add modules to the system, forcing them to learn a new language might be a bit too much to ask. Which would largely rule out the scripting language approach too, I guess.
Third option would be to use an actual c/c++ compiler, either bundled one or a system dependency. This would be rather complicated, and would add a noticeable pause whenever the code compiled. The positive side would be that the system could output synth .dll files (or, at least, compileable c/c++ files) that could be used outside the system, which would be neat. There's also things like cling out there which make the c++ compiler online, but I really don't want to have llvm as a dependency.
Of course, if the compilation only happened if the user specifically asks for it, or during boxing if the system supported that, that wouldn't be an overkill..
Additional positive side of using c/c++ compiler is that it should be pretty trivial to make a build that doesn't use the online compilation at all, and just take the performance hit.
MMXXI
January 17th, 2021 (permalink)
Year 2020, huh. That was. Well. Something.
There's a pretty thorough breakdown, and rather disappointingly empty pouet page.
So year in review. Everybody knows the covid messed up just about everything, but since my goals are mostly such that I can do them at home, that shouldn't be a reason.. but there we go.
A year ago I stated that I'd try to get some more hobby programming done. I can't really say that I'd made any great strides there. Music wise I did play around with making music and even streamed playing with my new Korg Wavestate a few times to massive audience of maybe 3 people =)
I'll just go ahead and give up on making goals. I have a bunch of things I'd like to concentrate on, and I might, but it's possible something else comes up.
Stuff, in no particular order:
SoLoud. I only managed one update last year, let's try to get to at least one update this year. If nothing else, there's an accumulated bunch of pull requests and 3rd party libraries to integrate.
DialogTree and by extension MuCho built on top of it. This is pretty much in the shape I left it a year ago. The idea here would be to get it to run on the Spectrum Next to allow people to create games. Maybe I'll whip a visual novel engine using DialogTree. First step would be to get a minimal DialogTree engine running on the next, though.
Music. I'll try to continue to play around with the synths I have, maybe even stream once in a while for people who want to torture themselves listening to someone fumble around. The long-term goal that I have is not to learn to play, but to learn to jam. It's all just for fun.
Finishing a game and getting it on Steam. I had this as a goal a couple years ago, and I still think it's a realistic goal if I just get around to it. I'm not looking to make the next greatest hit, but just to see what the process looks like and do it for the experience. Funnily enough, last time I made this a goal, 3drealms did it for me.
Finishing a hardware project. I have a bunch of them in some half- or even less finished states, including a usb racing wheel thingy and turning raspberry pi into a synth. These wait for major inspirations to advance. At least I managed to finish the hardware project that was required for the new year demo.
Getting in shape. I've found that moving snow is much harder for me, particularly my back, than it has been before. I should do something about it. I'm unlikely to do anything about it, but I should. I've heard good things about hula hooping, maybe I should learn how to. We'll see. Not holding my breath here. Round is a shape, right?
Things I'm more likely to achieve include working through my Steam backlog and watching Netflix. Both of which I could, in theory, manage while using an exercise bike, so there might be some way of getting the fit thing in there. Again, not too optimistic about it.
After 2020, it's pretty hard to feel optimistic about goals, really.