Blog
IR Webcam Addendum
November 8th, 2015 (permalink)
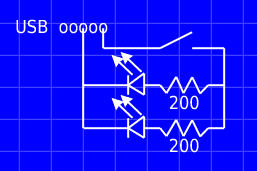
Got inspired to mod the webcam further, adding a couple of IR LEDs so that the camera can work without some other IR light source, as well as a switch to turn the LEDs off if needed.
When I opened up the case to check where I could drill some holes for the LEDs, I noticed that the case was actually designed for two LEDs to be fitted in it. I simply needed to dremel the holes open, put some glue on the LEDs and drop them in.

There was a hole on the backside of the camera, possibly for ventilation, or placeholder for some other designed but not implemented feature. I stuck the leads of a switch through the hole and glued the switch into the case. It's rather obviously tacked to the outside of the case, but I didn't have a small enough switch to put inside, but I still wanted to be able to disable the LEDs.. but it's not like this thing is going to win any beauty contests anyway.
Inside the camera, the board had five pretty large pads on a side with "USB" printed on them. Using multimeter I found that the + signal is the last one (furthest away from the "USB" print) and - is in the center.
I connected 200 Ohm resistors to the LEDs, and those to the switch, and from the switch to the + pad. The - went to the other end of the LEDs. After re-soldering a couple of times because my solders didn't survive closing of the case (sigh..), it's done and works.
So, what am I going to do with it? Still no idea. But now I'm in possession of a see-in-the-dark near-ir webcam. Which, I suppose, is neat.
ESCAPI 3
November 4th, 2015 (permalink)
Someone emailed me about ESCAPI (my simple webcam API dll thingy) a while ago. This in itself wasn't remarkable, considering that I've received well over a hundred emails about ESCAPI over the years, making it one of my more popular projects. This person was asking for a trivial change that would make his application work. I said it's been ages since I touched ESCAPI, but I said I'd try to get it to compile. After a couple hours of trying, I gave up - trying to get modern visual studio to talk with ancient directshow SDK wasn't as simple as I'd hoped.
Since webcams still somehow work, I figured there must be a more modern API, and, for the heck of it, rewrote ESCAPI from scratch using the windows media foundation API.
Like I said, over the years I've received plenty of mail regarding ESCAPI. The most frequent requests have been access to camera properties (which I didn't think was possible, and for some parts I was right), 64 bit builds, access to source code, and camera resolution selection. The new version covers all of those points as well.
The downside is that the new ESCAPI doesn't work with windows xp, but you can't have everything.
Since the build is on a modern visual studio and modern windows SDK, 64 builds were trivial. I stumbled on a stack overflow question on the camera properties while looking for something else, and put an API for those as well. It can't do everything - with my logitech camera I can't switch automatic gain control off, which is, however, possible using the logitech software. On the other hand, with the API I can adjust sharpness which is not possible through logitech's dialog.
The new ESCAPI also now tries to request the closest fit resolution from the camera. The old one just used whatever resolution the camera was set to. After doing that feature I found that windows 7 (and vista, and probably 8 and 8.1) have a bug where the capture doesn't always succeed for certain resolutions. This bug has apparently been fixed in windows 10, but you can't expect microsoft to back-port all their bugfixes, now, can you. So I had to add a workaround - if capture returns a failure, the resolution is marked as bad and we start over, until we find a resolution that works.
Since the resulting source code isn't quite as horrible mess as the directmedia source was, I've put everything on github. Knock yourselves out.
On top of these I also added a couple interfaces for checking if something has gone catastrophically wrong and to query the line number and HRESULT, so there's some minimal debugging aids. I hope nobody will ever need to use them, but they are there.
Finally, the new DLL should work as a drop-in replacement with the old, if you don't want to use the new features.
When I moved from XP to windows 7 I had to ditch my old webcams since the manufacturers didn't want to make new drivers, so I only had one webcam. Just to test ESCAPI I ordered a cheapo 15 eur webcam, and ESCAPI 3 apparently works fine with several cameras at once.
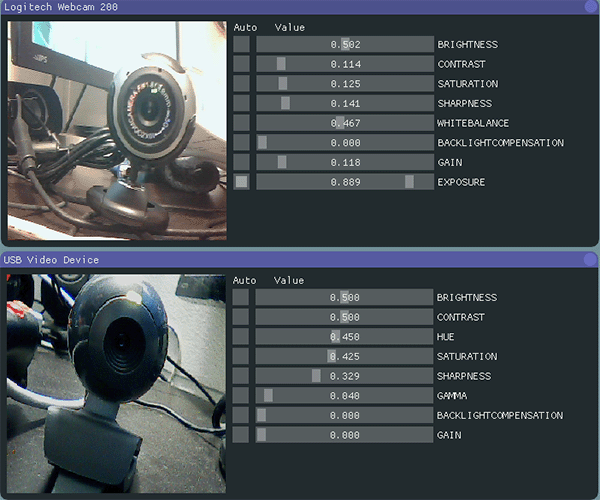
Note that the two cameras expose slightly different set of properties. There's also fun properties like panning and focus if you have a really fancy webcam.
Since I now had a cheap webcam with no particular purpose, I re-did the near-ir modification hack for it that I had done long ago for another cheap webcam - open the camera up (and got bit by the good old "screwhole hidden under QC sticker" trick), remove IR filter, replace filter with a couple layers of fully-burned film negative, and now I have a webcam that can't see (hardly any) visible light, but is sensitive to (near) IR.

I probably don't have any real use for it, but I do remember feeling bummed out when I found that my old "near ir" webcam no longer worked. Another thing has changed since - since we've moved largely to energy-saving lamps, our houses aren't as flooded with IR anymore, so for a IR camera everything is pretty dark. In the picture above, I have the two webcams side by side and I'm pressing a button on the remote control.
And yes, did already consider modding the camera further, as I should have a couple IR leds somewhere.
Photoshop Tutorial Video
August 25th, 2015 (permalink)
Folk at webucator asked if they may make video version of my firey texture photoshop tutorial, and I figured why not. I think it turned out pretty well.
Be sure to check out their photoshop courses as well.
On User Interfaces and Microwaves
August 24th, 2015 (permalink)

Microwave ovens are funny in that way that the user interfaces were pretty much perfected early on, and every improvement over that has pretty much just made things worse. But you have to keep innovating to differentiate yourself in the market.
To make it clear, the "perfect" UI that most microwaves have has one dial for power and another for time. These can be completely mechanic, but I've found that one worthwhile improvement is to show the exact time dialed as digital value.
While I worked for Fathammer at the HTC offices we had a microwave with about nine buttons with icons on them that did not have any clear function. The designers apparently understood the problem themselves, as one of the icons had additional tiny text "quick start", and that's the button most people at the office used. I learned to use the microwave well enough to actually set the clock (the procedure included opening the door) or to defrost food.

We bought a new microwave oven a while ago, primarily to get the digital time display, because making microwave porridge is highly scientific process. I hunted high and low for a microwave with a sane interface that would have this. I almost succeeded.
Since there's the digital time display, someone who's responsible for designing these things thought that it's a good idea to make the display show the current time - after all, there's a microcontroller in there, so it's all software, right? Except that they had to add a physical button to set the time. So what's bad about having a clock display there? Well, someone has to actually set the time, and remember to set it to daylight savings and back. And it's naturally not battery backed, so it needs to be set every time the device is unplugged (or if power is out).
On top of this, the geniuses felt it was necessary for the microwave to beep every minute after the time is out to remind the stupid users that yes, there's still food in the microwave. This is annoying beyond measure. I often nuke frozen food for 5 minutes and then leave it to even out temperature - and the microwave keeps beeping.
So yes, less is, surprisingly often, more.
I've never used either of the microwaves pictured here, I just picked a couple of different interfaces, so don't bother reverse-image-searching them.
Dice Tower
August 12th, 2015 (permalink)
I've been interested in making (or buying) a dice tower ever since I watched a video by Spoony about them. A few days back I googled a bit about schematics, as well as software for designing paper folding thingies, and finally just figured that I could just wing it. And wing it I did.
I started off with a small cardboard box, added three tilted planes inside it, cut out some bits, and taped the thing together.. and added some stickers.
Here's a simple ASCII schematic from the side:
.--- -.
| /|
|\ / |
\ /|
/ |
'-----'
Dice drop from the hole on the top, roll down the three slopes and end up at the bottom. Typically the dice towers have a "boot" form factor where the dice completely exit the tower, which is no doubt better usability-wise. Pretty much the only benefit of this form factor (apart from being really simple to build) is that it's easier to store.
Several people have asked me about whether the dice tower is "fair" or if it really produces random results. I did some practical research, and with a bunch of caveats I'd say that yes, it works well.
For the experiment I tried to drop the dice exactly the same way each time, the way you'd do if you'd try to cheat. In practice you just toss the dice in, so the result is way more random than in these tests, but the point was to find whether there's a clear bias or not. The number of tosses is also relatively small, so if I was crazy enough to drop the dice 1000 times there might be a more clear bias (or lack thereof). The dice themselves may also contain bias, and I didn't do a control for that. Finally, the problem with true randomness is that you never know if you have it.
For all the tests I aligned the dice so that the starting position is "1" with the numbers "right way up", so the alignment was always the same. I.e, if the die doesn't rotate at all, the result would be 1. For d4, I picked the face that has 1, 2 and 3 to face towards the front.
Here's the results, and some discussion:
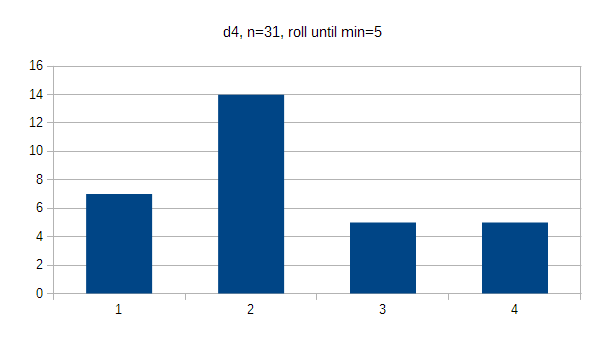
For the d4, I kept rolling until every option had a minimum of 5 hits. The results are pretty even, with the oddity of 2 getting 45% of the hits. I suppose if I wanted to cheat and got away with dropping the die in a specific orientation, I could gain some benefit - but in practice you don't get to align the die when you toss it in. If results were flat, every option would occur 25% of the time.
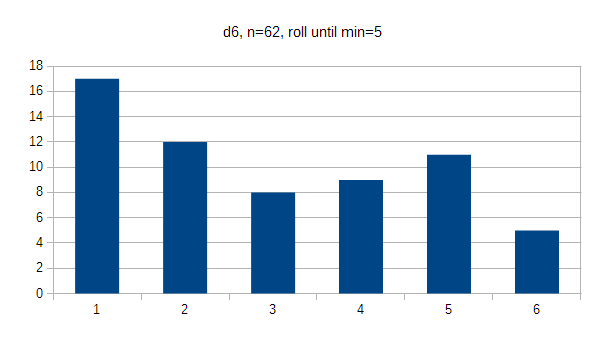
The d6 shows pretty clear bias towards 1 (27%) and bias against 6 (8%), suggesting that the die probably doesn't rotate all the way inside the tower. It may be worth mentioning that half of the 1:s I threw came in sequence, which may have been a statistical anomaly. If results were flat, every option would occur 16.7% of the time.
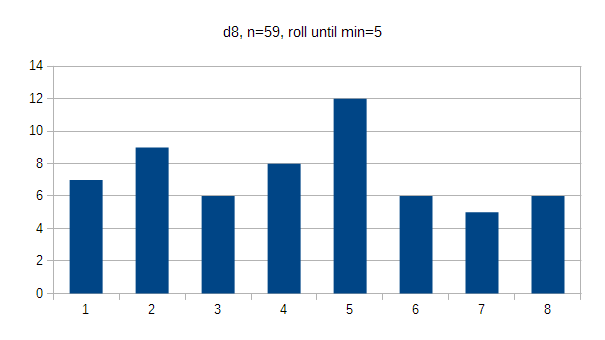
The d8's results are pretty flat. 5 appeared a bit more often (20%) than others, which may either be a quirk or symptom of how much the die rotates inside the tower. If results were flat, every option would occur 12.5% of the time.
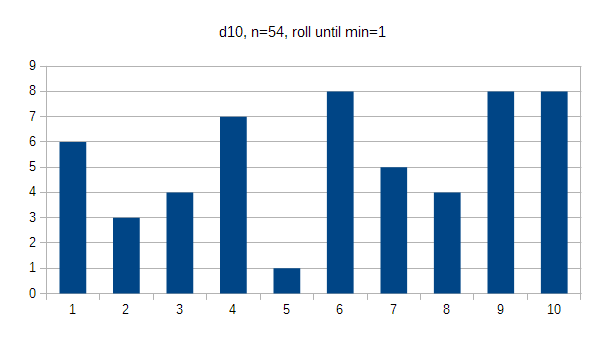
With the d10 it felt like it took forever to hit 5 (2%) for some reason, so I stopped when I finally hit it. The d10 is made so that even numbers are on one "side" and odd ones are on the other; even numbers were hit 44% of the time, which probably isn't significant. I'd say this is pretty random. In flat values every option would occur 10% of the time.
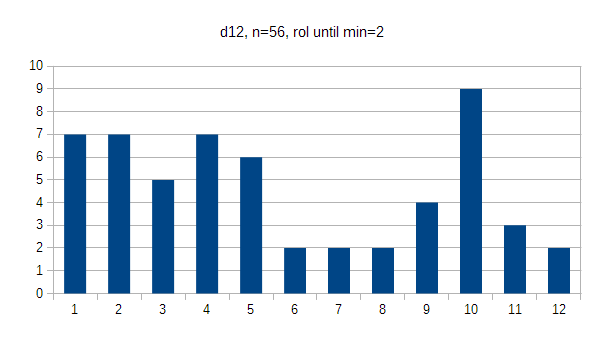
The d12 starts to be pretty round, and while there's a clear spike at value 10 (16%) I really wouldn't say there's any real significance there. I'd be more worried about the bias towards 1 (12.5%) instead of 12 (3.5%), but I'd want to see test with way higher n to be confident about it. In flat values every option would occur 8.3% of the time.
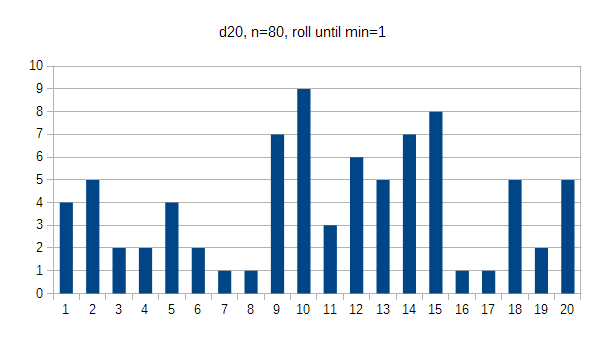
Rolling the d20 took way longer than the rest, not only because of the number of options, but because finding the 1 face and orienting it correctly before dropping took a lot more effort than with the earlier dice. The d20 is really round, and I don't see any clear bias in the data - if anything, 20 occurs more often (6%) than 1 does (5%). In flat results everyone would get 5%.
So there. The limited data suggests that it's not a perfect randomizer, but is still better than normal manual rolls. Also bear in mind that the results from your dice tower may be better than from mine - mine is just cardboard; towers with felt surfaces may force the die to rotate more. Higher towers will also put more energy to the dice than the small one I built.
If you're really paranoid, combine dice tower with a die cup. If that's not enough, maybe throwing dice is not for you =).
What cannot be denied is that it's fun to play with. Total build time was around 30 minutes: I spent more time writing this blog post.
Macgyver
June 18th, 2015 (permalink)
So I'm back watching Macgyver again, up to the third season already, and I'm seeing some patterns. Let's say someone wants to reboot Macgyver, what are the challenges compared to the original?
First, in almost every episode they're breaking the laws of physics. You have to give some artistic license of course, but still.. and I'm not talking about "macgyverisms", I mean other things. Like technobabble about EMPs, or bad guys shooting bazooka from inside a van. Hint: bazooka has "output" both ways. The van would get a bit.. hot. The world has changed, and information is more widely available, and the audience for a new Macgyver would prooobably be more knowledgeable than they were back then. So more research would be needed. Luckily the world has people like the mythbusters who could easily cook up all sorts of nifty things for the new Mac to jury-rig.
Second, the world has changed, and pretty much everybody is carrying a wirelessly networked supercomputer in their pockets. Many of the old Macgyver scenarios would be downright impossible in such a world, where you can both get information, track anyone who's carrying a phone, call for help, etc. And you can't really place every episode underground or in some backwater with no connection whatsoever or cause everybody conveniently to lose their phones.
Third, yes, the world has changed, and there's no cold war. A LOT of Macgyver episodes had a story based on comfy cold war scenarios where here's the good guys, there's the bad guys, but nobody wants to REALLY mess things up to cause an open war.
All that said, I feel the world needs a new Macgyver. The western world is moving further and further into disposable culture where nobody knows, is able, or is allowed to fix anything. We need inspiration to do things ourselves.
Second, I feel the new Macgyver should be female. Since Richard Dean Anderson is still around, the lead could be the niece or something of the original Mac. There's several benefits for the new fem-Mac - it's normal for women to carry around all sorts of stuff that could have "alternative uses". Consider jewelry, hair clips, not to mention the mobile chemical laboratory of a make-up kit. There would also be fuel for commentary on the impracticalities of women's clothing - where are all the pockets? Am I supposed to run in these things? Etc.
Edit: holy crap.
Talk about timing.
Gym Update
May 25th, 2015 (permalink)
As I wrote at the start of the year, I'm trying to get (more) into shape, and I'm using our basement gym three times a week. I started off by watching MacGyver episodes, which are about 45 minutes long, but then fell ill and wanted to take it easier so I switched to (the american version of) The Office, and watched three seasons of it. Those episodes are conveniently closer to 15 minutes long.
Having run out of episodes there (while considering buying the complete series), and not feeling like going back to MacGyver yet, I started on just playing music. But that's horribly boring; I felt I had to have something to do with my hands.
My wife manages to read books and comics while on the exercise bike, but when I tried that I found that I just couldn't do it. One friend of mine plays video games while on the bike, but I haven't felt like setting anything up in the gym for that. Then I got an idea.

Some years ago I bought, out of a whim, the solitaire chess. The idea is fairly simple: you have a 4x4 board and you have to figure out moves so that only one piece remains on the board. The game comes with 60 puzzles of increasing difficulty. At start I didn't even bother placing the pieces on the board as I could see the solutions outright. Later on I would solve 2-3 puzzles in one gym visit. Eventually I hit a puzzle I stared at for a couple visits before figuring out the solution.
It's worked great. When I started using it at the gym, I was surprised how fast time flied.
So far this year I've managed to keep up the pace of three times a week pretty well, only skipping when I've been ill, or had to do some heavy physical stuff otherwise. We'll see if I can keep that up =).
Let's do the sort
May 8th, 2015 (permalink)
I've been spending my free time on SoLoud audio engine again, working towards the next milestone. The project doesn't cease from surprising me about the things I end up researching for it. One of the key features in the upcoming milestone are virtual voices.
With virtual voices you can set up any number of voices (within reason) in your 3d space and then let SoLoud figure out which ones the player should actually hear. To accomplish this, we have to sort the voices by their volume (with a few exceptions). And sorting may be a bit slow.
Now, I knew that we don't have to do a complete sort, we just have to split the voices to two groups: those we do and those we don't hear. The order of either of the groups is irrelevant.
I started off with a partial bubble sort (don't panic) because it's dead simple to implement, and it promises that after N iterations the first N items are in their final places, so making a partial version was rather simple.
After I saw that the thing is working (with a test case even) I did some research. Turns out partial sorting is something people have actually researched, and there's even a partial sort in STL.
Since I'm not using STL in SoLoud so far, I wasn't interested in using that. Instead, I started hunting various sort implementations and did some benchmarking.
My benchmark suite generated an array of 1024 ints with values 0 to 1024 in them, shuffled the items by swapping random items using WELL512 rng, then used __rdtsc(); to time the sorting function, and finally verified that the result is acceptable, by checking both that the first 32 items were all the smallest 32 of the array, as well as checking checksum of the first 32 so that the data isn't just broken.
First, here are the results:
| Function | Cycles | |
|---|---|---|
| bubble | 5350k | |
| std_qsort | 324k | |
| partial_bubble | 201k | |
| quicksort_iterative | 217k | |
| rec_qsort | 158k | |
| optimized_iterative_quickSort | 154k | |
| rec_partial_qsort | 44k | |
| partial_quicksort_iterative | 22k |
All of the results above are averages from a couple thousand runs. Actual results will vary based on the content's original order as well as based on whatever your computer happens to be doing at the time, compiler options, the phase of the moon, etc. YMMV.
Let's take it from the top.
Bubble does the complete sort with bubble sort. I added this after benchmarking the others just for the giggle factor.
std_qsort calls the c stdlib qsort, and performs a full sort. I used this as a reference.
int cmpfunc(const void * a, const void * b)
{
return (*(int*)a - *(int*)b);
}
void std_qsort(int *data)
{
qsort(data, DATASIZE, sizeof(int), cmpfunc);
}
Partial bubble is what I started from, and for this particular data set it actually beats the stdlib qsort. When data (and/or subset) grows larger, the qsort naturally takes the lead.
void partial_bubble(int *data)
{
int i, j;
for (i = 0; i < SUBSET; i++)
{
for (j = DATASIZE - 2; j >= i; j--)
{
if (data[j + 1] < data[j])
{
int t = data[j];
data[j] = data[j + 1];
data[j + 1] = t;
}
}
}
}
Next is an iterative quicksort I found on a wikibook page comparing quicksort implementations. I believe these to be in public domain.
Surprisingly, slightly faster than that was a recursive quicksort:
void rec_qsort(int arr[], int beg, int end)
{
if (end > beg + 1)
{
int piv = arr[beg], l = beg + 1, r = end;
while (l < r)
{
if (arr[l] <= piv)
l++;
else
swap(&arr[l], &arr[--r]);
}
swap(&arr[--l], &arr[beg]);
rec_qsort(arr, beg, l);
rec_qsort(arr, r, end);
}
}
I also found this optimized iterative quicksort which turned out to beat the other full sorts in this set. I did not manage to make a partial sort version of that (as of yet).
I did make a partial version of the recursive quicksort though. I'm not 100% certain my implementation is correct though, but here it is:
void rec_partial_qsort(int arr[], int beg, int end, int k)
{
if (end > beg + 1)
{
int piv = arr[beg], l = beg + 1, r = end;
while (l < r)
{
if (arr[l] <= piv)
l++;
else
swap(&arr[l], &arr[--r]);
}
swap(&arr[--l], &arr[beg]);
rec_partial_qsort(arr, beg, l, k);
if (beg < k - 1)
rec_partial_qsort(arr, r, end, k);
}
}
I didn't like the idea of putting a recursive function in SoLoud though, so I also made a partial version of the (non-optimized) iterative quicksort, which turned out to be faster than the recursive one.
void partial_quicksort_iterative(int *data, int len, int k)
{
int left = 0, stack[24], pos = 0, right;
for (;;) {
for (; left + 1 < len; len++) {
if (pos == 24) len = stack[pos = 0];
int pivot = data[left];
stack[pos++] = len;
for (right = left - 1;;) {
while (data[++right] < pivot);
while (pivot < data[--len]);
if (right >= len) break;
int temp = data[right];
data[right] = data[len];
data[len] = temp;
}
}
if (pos == 0) break;
if (left >= k) break;
left = len;
len = stack[--pos];
}
}
The code I put into SoLoud is based on that version - not exactly the same, but close enough.
All of the partial sorts I found actually did a better job than I needed, having the partial part sorted, so I believe there might be an even faster algorithm out there for this exact case.
But hey, 10x speedup!
Video Production
April 10th, 2015 (permalink)
I did the keynote video for Ludum Dare 32.
This was my first "real" video production - there's a bunch of videos on my youtube channel but they're all mostly just screen captures of whatever stuff I have worked on. This time I had video recorded with a camera, separate audio recorder and bunch of video editing.
It was more work than I expected.
First, the equipment - I've wanted to buy a GoPro, but haven't really had a use case for it before, so this gave me the excuse to buy one. GoPro is a relatively cheap, rugged camera with full HD recording and a rather wide lens. The wide lens bit made it less suitable for this project than I had hoped, but more of that later.
Audio was recorded with my Zoom H1, which is a cheap but surprisingly good standalone stereo mic, which can also be connected to PC with USB and used as a PC microphone (unlike the gopro, which can only be connected to a PC as a USB disk drive). I did some further processing in Audacity, I felt the sound was too "thin", so I also ran the sound through some Guitar Rig filters, which unfortunately did end up making the voice sound like it's in a room instead of the outdoorsy green-screen thing I was going for. Oh well.
Talking of green-screen..

I set up a "ghetto" studio in my basement, using a green blanket as the green-screen. GoPro's very wide lens made the framing rather difficult - as a rule of a thumb you should have as much space between the people and the green-screen as possible to avoid shadows casting on the screen, but I had to place the camera rather close to the screen and squeeze myself between these to make the framing work at all.
Even at the distance you can see in the picture above the GoPro can see the whole blanket and actually even further, so after capture I only use cropped part of the video. This works out fine since GoPro captures at 1080p and the output product was 720p.
Framing was also rather difficult with the bare-bones GoPro Hero as it doesn't have a screen. I had to take some experimental photos and/or video, detach the camera from the tripod, run to my computer to download the stuff to see how the framing goes, do some adjustments and repeat until I was more or less satisfied with it.
I noticed from these edits that the lighting on the blanket was really uneven, so I set up more (and more) lights in the room to even things out. These naturally generated more and more shadows all around, especially since I couldn't have a lot of space between myself and the screen, but overall these new shadows were not as dramatic as with the original lighting setup.
Once the setup was done, I took a few takes and started working on the editing. I had to tear down the studio as the room is used for other things as well - such as drying laundry - so like in "real life", my studio time was limited =)
Unfortunately the first takes were rather bad, so I had to redo the shooting later on. I was ill a few times in between, including a rather long-lived influenza, which postponed the re-shoot uncomfortably close to the deadline. In the end I did end up setting things up again and did a few new takes. After that it was a matter of picking the take I hated the least and going with it.
I could have edited several takes together but, come on, it's just 3 minutes, I wanted it to be a single take.
Also, you may not notice, but the background forest is not a still image but video recorded from a forest nearby. It wasn't a particularly windy day, but you may notice some of the branches moving.
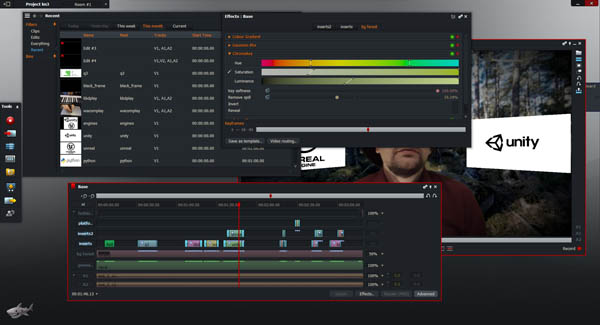
I used LightWorks, as it comes highly recommended, has some impressive things in its portfolio, and can be used for free as long as you're fine with some limitations (such as limited export formats). If LightWorks is representative of what Hollywood movie folk have to deal with, they have my pity. Seriously. This is version 12 of the software, and still it has really strange limitations and unintuitive actions.
Everything orbits around the idea of scrolling film back and forth and marking bits for deletion, etc. That bit works fine. Matching audio tracks? Okay, I'll just drag the audio sideways to match the 'click' signals together. Nah, we won't let you do that, instead let's reset the zoom to "I can see my house from here" and stop the drag. What.
Okay, so I get the audio matched by "cutting the film" of just the audio track eventually. Let's add fade in and out... uh. there's no such filter for audio.
So I ended up doing the "audio matching" in audacity in the end, re-importing the audio a few times. I didn't remove old imports because when you try to, you get a really scary warning dialog about it, and I wasn't about to start all this work from scratch, so I just lived with 10 copies of the soundtrack being in the project.
As for the video effects, well, some of it is a snap, other things less so. When things get a bit more involved you'll edit the filter chain.
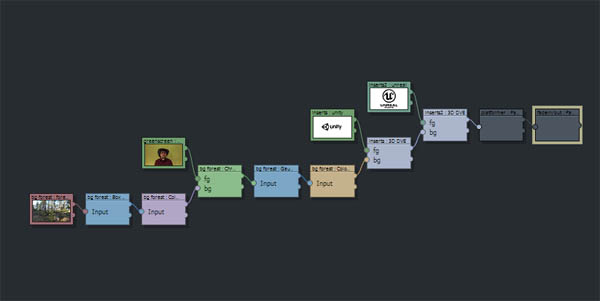
This is fine, nifty, and rather powerful, until you disconnect one wire and half of your graph disappears and you're in WTF-land, or you find that some boxes can't be wired to or disconnected, and there's no explanation on why any of the above happens. Eventually you start from scratch and get things working more or less, but it's rather frustrating.
Remember, I'm assuming we're talking world-class bleeding-edge stuff here. If this was some open source hobby project it would be great!
On the positive side, the software only crashed once during the whole 3-minute-video project, I did get the video out - with some glitches I could have fixed, but the biggest glitch is the acting which I can't do much about =). The green-screen stuff works great, even with my "ghetto" setup. My PC isn't exactly the highest of high end anymore, but the software only occasionally caused some hick-ups - most of the time it was smooth and did what I expected it to do. At least after learning not to try to do some things.
I didn't mean for this to be a rant about LightWorks, really, and it's not as bad as I may make it sound. I haven't tried any other video editing software, so I don't know if there's anything better out there - I know there's plenty of WORSE stuff, though.
But really, it's a great piece of software. Just not exactly what I was expecting.
Anyway, I hope you enjoyed this little piece of "behind the scenes", and have fun in Ludum Dare, whichever is the next one at the time you're reading this =)
Broken Telephone
April 2nd, 2015 (permalink)
A few days ago I got inspired about the idea of making a "broken telephone" based on soundex codes. I ran an English dictionary through soundex and stored various words for each code produced. The result can be found here - the result works, more or less, but it was a bit of a disapointment. As in, not funny.
The biggest technical challenge with the soundex was implementing the soundex algorithm itself. You can look at the page source for a javascript implementation.
Considering how to make it funnier, I figured that using a thesaurus instead might work better. I found a public domain English thesaurus, and made a similar database based on that. The result can be found here, and it's much better.
There was one fun technical challenge with the thesaurus - it was 25 megabytes, which is slightly big for a web page.
First, I pruned the dictionary from terms I can't use, ditching all multi-word terms. I also ditched any terms that did not have a definition. Finally, I stored the words by their index instead of longhand. The resulting json was 7.8M.
Since the indices took the largest part, I figured I could just sort the indices by the frequency they're referred to; the most frequent 10 would then take one byte, the next 90 two bytes, the next 900 three bytes, etc. The savings were pretty minimal (down to 7.1M). I removed that optimization and used delta encoding, where the current index is the sum of all previous indices; this worked much better (down to 5.1M). Doing both the sorting and delta yielded slight improvement, so I opted not to use it.
As an alternative, I considered encoding the indices in a string instead - since there are 25000 words in the dictionary, we'd need 15 bits. These encode pretty easily to three characters each. In array notation the minimum size one index can take is two bytes (number and comma), while in this notation it would always be three. The result was smaller (down to 4.4M), but the javascript would have been more complex, so I didn't feel it to be worth it.
The next step, which I didn't take, would have been to encode the indices at variable number of characters based on the index size; this would have made the decoder even trickier, so I didn't bother with it. Also, since the final file is run through gzip, compressing twice isn't a good idea.
So in the end I just opted to simply use the delta encoding. The result is still quite big (2 meg .gz file), but it's far from the original 25 megs.
ProcTree
January 15th, 2015 (permalink)

At some point in the past I wanted to have tree meshes in some project or another. I can't really remember what the project was. Point is, there weren't any good, free solutions for this out there.
Couple years ago I stumbled upon snappytree, or more precisely proctree.js that powers it. It's a liberally licensed procedural tree generation library, which unfortunately was in javascript.
I pondered on rolling my own at some point, then considered on just porting proctree to C, but due to my lack of javascript experience the first attempt failed miserably.
Fast forward to a week ago or so, I got inspired to try porting again (having played around with javascript via codecademy at some point in between), and voila: c++ port of proctree is here. It benchmarks at about 9000 trees generated per second on my machine, which should be sufficient for most uses.
I also wrote an editor for it called HappyTree. The sources to the editor (and link to a win32 binary) can also be found on the github page I liked above.
Microspikes
January 5th, 2015 (permalink)

This is a little product endorsement I've been meaning to write for several years, but haven't for one reason or another gotten around to it.
Kahtoola microspikes. Who honestly don't pay me to write this. I wouldn't mind if they did, but they don't.
With the weather in Finland being what it is, the streets are often deadly slippery during the winter. Oh sure, they do sand the ice (when they get around to it), but that doesn't really solve the issue. People don't slip on ice because it's slippery. People slip on ice because it's surprising that it's slippery. If you expect the surface to be slippery, you walk in a different way to avoid falling down.
In that kind of weather taking a 20+kg dog out for a walk can be stressful, because the dog has more traction than you do, and if for some reason or another the dog decides to start pulling you somewhere, it may be difficult to assert who's making the decisions.
But not with these babies. Oh no. While wearing these, you don't need to care where you step, or how. While other people are shuffling around carefully, you can just go past them with confident strides.
Pretty much the only surface that I've found to feel slippery with these on are metal manhole covers. I especially like walking on thick ice with these, as they bite in quite well. Another slightly problematic surface is near-zero degree snow, which may get stuck in the bottom of your shoes. That's not as big of a problem as you might think, though.
The biggest negative is that you can't walk indoors with these (with a straight face anyway), so entering a store requires you to take them off (and to carry a bag with you to put the wet things into while in the store), and to put them back on. Taking them off isn't much of an issue, but putting them on takes a bit more effort. With some practise that's not difficult either, but it's another small hassle.
At home we just use a thick doormat onto which we can step with the spikes, and don't bother taking the spikes off.
They're definitely more expensive than your average teeny-tiny spike rubber thingies you might use, but they're definitely worth it just for not having to care about slippery surfaces outdoors. And yes, you'll definitely have more traction than the dog, too.
Welcome to 2015
January 2nd, 2015 (permalink)
Welcome to 2015. To start off, here's the new year demo..
..with discussion on Pouet, and a short breakdown writeup for you making-of lovers.
Let's see what's going on with my self improvement tasks;
- Writing. Apart from stuff on this site, SoLoud has a lot more documentation now. Should probably do other writing too. Not quite sure what, as of yet.
- Music. Didn't really focus on this last year, "doodled" every now and then but didn't record much of anything. Drooled over some new Native Instruments synths, but haven't thrown money at them. Yet. Should spend a bit more time on this and get at least some simple song structure going.
- Getting in shape. This hasn't played a big part so far, but is going to get more in forefront in 2015.
On the topic of getting in shape: Based on weight index my weight is "normal", but that doesn't mean that I'm in a good shape. I'm turning 40 this year (eek), and in my 5-year checkup they found some worrying figures. So I was put on cholesterol medication, on top of which I've started to use our basement gym a couple times a week. I'm working through the McGyver episodes, 30 minutes on exercise bike and 15 minutes on weights, to start with. I'm planning on keeping that schedule unless something exceptional happens (like being sick or on a trip somewhere).
With 139 episodes of McGyver total, that should be enough distraction at the gym for at least a year, even if I occasionally did three days a week.
On hobby project front, SoLoud remains the 'big' project, even though I haven't touched it for a few months now. There's still a plenty to do there. I'll probably update couple other projects that depend on SoLoud (game projects mainly) to push myself to add some of the missing features.
I've also started following Casey Muratori's excellent hand made hero series, where he streams building of a game from scratch with little to no offscreening, and following that has caused me to ponder a few other game types to build as well. Too many ideas, too little time..
I'll also probably dust off some other old projects of mine this year and release the sources. Cleaning up HORS for instance, and plugging SoLoud to it, might be a fun nostalgy trip. A lot of pages on this web site are in need of updating, even if just to add a notice that the information is out of date (like most of the emscripten tutorial).
I'm also planning on applying to study teaching, but I'm not holding my breath on that, as there's way more applicants than starting positions, and they prioritize people who already do lecturing on a professional basis (and my single course gig doesn't really count). The course I'm applying for is done completely remotely, and I could do it alongside my job. If I do get in, I won't have any trouble with free time this year, so not getting in may also be good news.