Speccy, Vol 11: QuizTron 48000
June 11th, 2016
Another speccy thing already? Well... yes. I wrote the "Rotten Egg Mines" a while ago, but wasn't sure if the competition rules allowed me to talk about it or to give the .tap file away, so the blog post got postponed a bit. After I got the OK from the contest organizers I did all that.
Meanwhile, I was working on a trivia game engine.
Inspired by a thread on world of spectrum on trivia engines I googled for some trivia question sets, and happened upon one that I believe I could use. The set was part of a home automation perl script project (of all things), where the source code was GPL but data did not have a license. I presume using it on an unlicense-based, free game is okay.
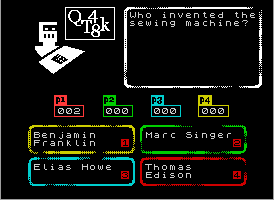
Anyway, said set had questions on entertainment, sports, science and mixed bag, each set having 500 questions except for the mixed one only having 250. A question set of 500 questions was about 77kB, way too much for the speccy. When I converted the data from fixed-width fields to pascal strings (as in [string size byte][n bytes of string]), this dropped to about 51k. I clearly needed to figure out a way to compress the data.
Hitting the whole data set with ZX7 or some such wasn't an option because I needed to be able to unpack random strings from it, preferably quickly. I opted for a dictionary approach, where the high bit of a character says whether it's a literal character or index to the dictionary. As an example, a compressed string looks like:
"[H o][w m a n y][ f i l m] s [d i d] E l v [i s] | -> cont'd
Raw data : 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4
Compressed: 1 2 3 4 5 6 7 8 9 0 1 2
P [r e] s [l e][y ] m a k [e ][i n] h [i s] [l i] f e [t i][m e] ?"
6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 = 54 bytes
3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 = 32 bytes
So for the example string, uncompressed is 54 bytes, compressed is 32 bytes, which is a relatively good compression ratio considering that you can decompress any string of the 1250 strings in the final application extremely fast.
To generate the dictionary, I first generated all the 2-10 character substrings of the whole question/answer set, searched how many times each of those match, sorted by potential value. The first order isn't optimal because you might get a lot of hits for "the", but if "is the" eats the "the", it'll get fewer hits on actual compression. So I gather the actual hits, re-sort, try compressing again, and repeat this as long as the compression ratio improves.
"Potential value" there is word length times frequency minus how much it takes to encode and how much it grows the dictionary, so five "for":s (5*3-(5*1)-(3+1)=6) beat two "elvis":es (2*5-(2*1)-(5+1)=4) easily.
I'm pretty sure there are better algorithms out there, even ones that would produce the absolute most optimal dictionary, but what I wrote gave me a compression ratio of 27% on average, which I feel is pretty good for a byte-based, dictionary-based approach. Remember, we need to store the dictionary too!
The data size was still rather large (32kB), but within reason. I decided, mostly because the "mixed bag" data set only had 250 questions, to split the bigger data sets in two, resulting in 7 sets of 250 questions. Each of these, compressed, resulted in files that are about 17kB, which is pretty usable size.
With the screen memory, followed by the question database padded with one full screen image (uncompressed), 2/3 of the 48k was in use.
Mackarel 2.1 by Jari Komppa, http://iki.fi/sol
Progname set to "QT48k07 "
"crt0.ihx":
Exec address : 49152 (0xc000)
Image size : 8585 bytes
Compressed to: 5165 bytes (60.163%) by ZX7
"mixed.scr"
Image size : 6912 bytes
Compressed to: 1558 bytes (22.541%) by RCS
"lowblock.dat":
LowBlock addr: 23296 (0x5b00)
LowBlock size: 22539 bytes
Compressed to: 14578 bytes (64.679%) by ZX7
Boot exec address: 45502 (0xb1be)
BASIC part : 51 bytes
Screen unpacker : 122 bytes
App bootstrap : 123 bytes (69 codec, 54 rest)
"qt48k07mixed1.tap" written: 21651 bytes
Estimated load time: 154 seconds (16 secs to loading screen).
Memory : 0 2 4 6 8 10 12 14 16
|-------|-------|-------|-------|-------|-------|-------|-------|
On load: rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
sssssssssssssssssssssssssss..b..................................
..................................................BLLLLLLLLLLLLL
LLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLCCCCCCCCCCCCCCCCCCCC
On boot: rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr
sssssssssssssssssssssssssssLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLL
LLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLL............
CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC..............................
Key : r)om s)creen b)asic L)ow block C)ode block
H)igh block .)unused -)reserved
The compressed application image was in fact so large that I found a bug in Mackarel, where a sanity check was too zealous and didn't allow me to move the code start address that high.
Anyway, I had about 16k to make the actual game. Easy enough. After adding all the necessary code (including the main menu cutscene) I had used over half of that space, at which point weird bugs started to creep in.
The thing is, when writing stuff in C, you don't have as absolute control over what's going on as you would in assembly, so the remaining memory still contains stuff like the stack and global variables - I don't know how much free space I actually had. However, I shuffled things around a bit and got the weird bugs to disappear. Since the game was feature complete, I didn't bother investigating further. I'm probably wasting 3-4kB of memory (including the bits between the low block and the code block), but I'm fine with that just for the convenience of C.

Speaking of the main menu "cutscene", I spent way too much time designing the evil announcer robot. The speech and eye animation are completely written in code, which was more work than it's worth. On the other hand, I didn't need to add more content. Originally I thought about doing four frames of animation and storing those and doing block copy, which would have given more freedom for the art, but on the other hand, would have taken more memory. The "mouth" movements are directly from the letters used, and the eyes move up and down periodically. It's a robot, so I think that's enough.
As you may notice from the Mackarel report, the low block gets compressed quite a bit with ZX7, so it manages to compress my compressed strings even further. Some 7k of the low block is the raw background image which probably also gets crunched quite a bit.
If I wanted to add features, I'd probably compress the background image and only decompress as needed. Or even leave it as is and overwrite its space in memory after it's been copied to the screen.
And yes, the background image is again done using Image Spectrumizer and Photoshop. That part of my toolchain (still) works like a charm. I did think of a couple new features I want in the Image Spectrumizer that would help software development though, we'll see if I get around to implementing them.
Back to the game!
When the game needs a new question, it picks one at random and decompresses the question and answer strings for faster access later on.
As I hinted before, the questions and answers are stored as pascal strings, as is the compression dictionary. First 120 strings are the dictionary, and the 1250 strings after that are the 250 question + 4 answers sets. To find a specific string, simply start from the beginning, read a byte, hop forward, read a byte, etc, until you're there. It only takes a maximum of 1250 hops to get to any string.
The application calculates pointers to the dictionary entries to speed up the decompression, though. This probably wasn't necessary, but it simplifies the decompression code a lot.
The whole string finding and decompression is fast enough that I didn't need to do an optimization pass on it; I don't even notice any delay on starting a new question. It may take a frame or two, but the game is so slow paced that it doesn't matter.
For random, I used the xorshift8 and xorshift16 random generators, which work with few bits (i.e, no need for 32 bit or 64 bit ints) and don't require multiplication or division. For more "real" randomness, I keep running the random number generators while waiting for keypresses. There's no attempt to avoid duplicate questions, so even though there are 250 questions to choose from, it's entirely possible to get the same question twice in one game.
The rest of the application itself was pretty much just work - helper functions to set the bright attribute of answers and players, printing the different players' keys, the game loop, printing out score, etc. I didn't need to write any new z80 assembly code, everything was fast enough.
Some more interesting stuff happened on the preprocessing side, however. I noticed that the trivial word wrapping I had done wasn't good enough.
Consider the following..
|123456789012|
"Efram Zimbalist, Jr" - Too long, wrap
| |
"Efram
Zimbalist, Jr" - Too long, wrap
| |
"Efram
Zimbalist,
Jr" - Oops, too many lines
The fields are not only narrow, but also have limited lines!
And naturally there were things like..
|123456789012|
"Chloropromazine" - Too long.. can't wrap
But there were also plenty of cases which could be wrapped nicely if the algorithm was smart enough.
|123456789012|
"Mid-afternoon" - Too long.. can't wrap
So I rewrote the algorithm so that first we try to wrap everything on spaces. If that fails, we try to wrap nicely - after dashes, dots, etc. If that fails, we'll just cut wherever. The result for these three strings would be:
|123456789012|
"Efram Zimbal
ist, Jr"
"Chloropromaz
ine"
"Mid-
afternoon"
Even more optimal would be to first fail, find the shortest line, remove newline, suggest a word break on offending word, and repeat until done. That would (hopefully) only make one word awkward, whereas in this scheme, if the "nice" approach fails, nothing gets wrapped.
However, unless a question contains over 16 character long words, the questions won't go to the "brute" method. That means that the "brute" method should only apply to the answers, which may only use two lines in any case.
For sound, I used BeepFX again, creating a bunch of small beeps for the QuizTron's speech, and three effects for menu selection, correct and failed answers. After sprinkling these in (and fixing the nearly-out-of-memory bugs mentioned above) I'm finished with the engine.
If I really wanted to, I could create more content packs for the QT48k, but it's unlikely that the game will gain popularity, as we're talking a niche platform and a niche game type. A math trainer would be pretty easy to do, generating the questions and answers algorithmically (Q: "X oper Y" A: +-1, +-1X/Y wrong answers). Others would require... more work. Unless I stumble upon other data sets I could easily use, of course.
Anyway, as a project it let me play around with compression and word wrapping at least, which was pretty interesting.
The game itself is exactly the same in all of the cases, only things that differ are the data set and loading screen. I considered giving the robot something different to say per data set, but didn't bother with it. In retrospect I could have made the "cutscene" completely data driven (it's just a bunch of pascal strings, after all) instead of compiling it in, but, oh well.
Pack 1: Entertainment 1 tap file qaop online emu.
Pack 2: Entertainment 2 tap file qaop online emu.
Pack 3: Science 1 tap file qaop online emu.
Pack 4: Science 2 tap file qaop online emu.
Pack 5: Sports 1 tap file qaop online emu.
Pack 6: Sports 2 tap file qaop online emu.
Pack 7: Mixed bag 1 tap file qaop online emu.
The source code is on GitHub as usual.
The source of the questions is this github repo.
I'd be curious to hear if someone actually plays a 4-player blitz game on actual speccy =), but that's probably too much to hope for..